Abstract
This thesis
describes the use of an existing SIMD (Single Instruction, Multiple Data)
subroutine library in order to speed the execution of Java programs on MMX
capable CPUs. We have developed a technology that makes use of a method
substitution system which dynamically links the library on the appropriate CPU.
The library is downloaded and the library paths are corrected at runtime, so
that the user can have seem less speed-up experience. Our tests show an
average-time speed up of 3 – 6 times.
1. Introduction
The goal of this research is to improve the performance of some Java
programs by using the SIMD architectures (i.e., those that enable the fast
processing of vectors via fine grained parallelism) via native methods.
We wrapped a SIMD library [33] using java.
The library utilizes the registers present in the modern Intel processors and
enable x86-based computers to accelerate the execution of java programs. At
present, this code works for Linux based x86 processors with the MMX ability.
1.1
Problem Statement
We are given a SIMD-capable machine (MMX) and
our goal is to make use of this instruction set in order to accelerate our Java
programs. A series of experiments were conducted to demonstrate the speed-ups
that are available for the code that makes use of the SIMD architecture present
in the vector-processing unit. We are able to obtain typical speed-ups between
3 - 6 times.
1.2
Approach
The vector-processing unit has a set of
registers, which are often unused by the java run-time. There are several
subroutine libraries available which are already tuned to take advantage of
these instructions. Performance speed-ups are achieved by forcing the virtual
machine to use these registers for computation intensive methods via native
calls.
Our approach to this research is to wrapper
the given MMX accelerated native libraries, using Java, and to benchmark the
execution of said program on a variety of algorithms including matrix
multiplications, and a Dhrystone benchmark.
1.3
Motivation
Modern CPU’s are equipped with vector
processing units, which have additional set of registers and are rarely used.
As in the case of Java, slow performance is an important drawback. The Java
virtual machine does not know how to use these vector processing units. In this
thesis we introduce explicit calls to the vector processing units for
computation intensive methods, via native libraries. This compels the Java
virtual machine to use the available registers in the vector processing unit.
Considerable speed-ups in execution can be achieved in this manner. This will
lead to an improvement in the performance of programs written in Java.
2. Related Work
Considerable research has been done to enhance Java performance. Java seems to have problems with the way it organizes and manages multidimensional arrays, which pose performance problems; customized array packages have been developed to address these problems. These arrays are used for high performance computing, they have their own set of invocations to perform array computing in optimized fashion [11, 13, 15, 17]. Exception management seems to add overheads to Java performance, techniques to eliminate unwanted exception have been proposed. In cases where exceptions are used in iterations, worst case in nested iterations; algorithms exist to modify the bytecodes, such that these iterations could be wrapped into a single exception, there by reducing the overheads, and contribute towards performance speed-ups [4]. Since FORTRAN, C and C++ seem to perform better than java, techniques have been proposed to convert java source or bytecodes to native language, may be C, C++, ASSEMBLY or FORTRAN. Sometimes, profilers [18] are used to detect methods which are computational intensive, and use most of the execution time, such methods are converted to native code, and wrappers are generated for such native and code and placed in the bytecodes, such that these invocations would use the native code, instead of the java code. Hybrid compilation models have been proposed, selection strategies are used there may be more than one method waiting to be translated to native code due to the concurrent execution, the decision as to which method must go first will effect the performance of the VM, such decisions are made on the basis of historical runs. On the other hand the selection can be made between JIT and interpretation [12, 20]. Other techniques include manipulation of the JIT to the working of the virtual machine [2]. Considerable research as to how the underlying hardware architecture could be used to enhance Java compilation techniques is described in [1, 17]. Just In time compilation Heuristics have been proposed to manipulate bytecodes to take advantage of the hardware architecture organization. Such heuristics, target specific architecture like IA64 [9, 10]. Tools and algorithms exist which can automatically detect implicit loop parallelism and exploit them at bytecode level [3, 5, 6, 7, 16].
3. Analysis of some Existing Java Virtual Machines vs.
C Compiler
There are several virtual machines available, some are based on the SUN Microsystems virtual machine [21] and other virtual machines exist, which are independent of the SUN Microsystems implementation, like the GCJ for Linux. Each of these virtual machines has its own perspective to compile and run programs. The graph below depicts some of the Virtual machines and their performance. The benchmark used is the Dhrystone benchmark. The Dhrystone benchmark is executed for 500000 cycles in each case.
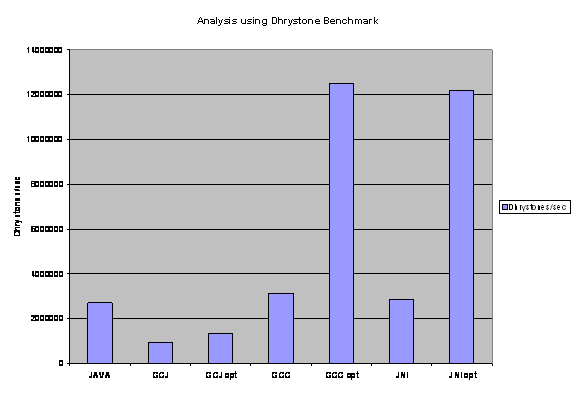
Fig 3.1 Analysis of Dhrystone benchmark
Note: Opt refers to compilation with
optimizations on.
The graph clearly indicates the performance of C is comparatively better than any java virtual machine. Results clearly indicate that the performance improvements are achieved due to the introduction of native methods. In this thesis we attempt to achieve better performance by using native code via JNI from Java. There are several other high performance libraries for scientific and engineering purposes, like the JAMA [22] Java matrix high performance library for matrix multiplication, purely implemented in Java. Another pure java high performance library is Lyon & Rao [23], a library that they wrote for their book. The Java Advanced Imaging library uses a combination of native code and Java to obtain speed-ups. InAspect signal and image processing package for java exists which target essentially embedded systems mainly. [24]
4. MMX Overview
MMX is an improvement, added to Intel
processors. The chances of existence of MMX registers in any modern computer
you purchase are very high. The MMX registers present in these modern CPU, can
boost performance anywhere between 5% - 20%. Dramatic performance gains are
obtained on applications which are compiled specifically, to use the MMX instruction
set. There are 57 instruction sets that can be used to manipulate these
registers; these can also be used by applications to take advantage of the
underlying architecture.
Pentium processors with MMX also use a technology known as Single Instruction Multiple Data, or SIMD. In a nutshell, this technique allows the chip to reduce the number of processing loops that are usually associated with multimedia functions. By utilizing SIMD, the same operation can be performed on multiple sets of data at the same time [36].
The MMX technology added 8 registers, to the architecture. They are numbered from MM0 – MM7, or simply referred to as MMn. Each of these registers is 64 bits wide. In reality, these new "registers" were just aliases for the existing x87 FPU stack registers.
The MMX technology
also introduces four new data types: three packed data types (bytes, words and
double words, respectively being 8, 16 and 32 bits wide for each data element)
and a new 64-bit entity.
The four MMX technology data types are:
![]()
Packed byte
-- 8 bytes packed into one 64-bit quantity
![]()
Packed word
-- 4 16-bit words packed into one 64-bit quantity
![]()
Packed double word
– 2 32-bit double words packed into one 64-bit quantity
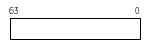
Quad word --
one 64-bit quantity
Let’s
consider an example where pixels are represented by 8-bit integers, or bytes.
With MMX technology, eight of these pixels are packed together in a 64-bit
quantity and moved into an MMX register; when an MMX instruction executes, it
takes all eight of the pixel values at once from the MMX register, performs the
arithmetic or logical operation on all eight elements in parallel, and writes
the result into an MMX register. The degree of parallelism that can be achieved
with the MMX technology depends on the size of data, ranging from 8 when using
8-bit data to 1, i.e. no parallelism, when using 64-bit data [8]. The MMX
instruction set cover several functional areas, arithmetic, comparison,
conversion, logical, shift operations, data transfer and state management.
For typical MMX syntax refer Appendix
A
The Java virtual
machine does not know how to use these additional registers. In this thesis we
attempt to force the usage of MMX instruction set, via native calls to C
libraries which have the MMX/SE2 instruction sets in lined.
5. Method Substitution and SIMD Library
The working system can be categorized into a method substitution module and a SIMD library module.
5.1 Method Substitution System
The method substitution system can take bytecodes as input. The program will span bytecodes and recognize the methods which can be accelerated. The program also gives an option for selective acceleration of methods.
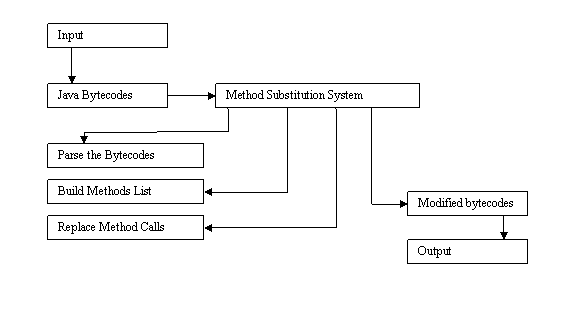

Fig 5.1.1 Method substitution system
The heart of the method substitution system is a text file. The text file consists of method prototypes, which have to be detected and their equivalent accelerated functions. In this way the user has full control over the methods replaced by the method substitution system. The method substitution system uses Javassist [32], to read class files, and builds a list of existing methods and replaces the method calls at bytecode level.
Working of Method Substitution System
Assuming this line exists in the prototype text file
getSQRT ( float )float -- nativeImplementation.MMXMath.sqrt($$)
This infers the name of the method to be searched is getSQRT, which takes one parameter of type float and also returns value of type float. Once this method is found the call will be replaced with nativeImplementation.MMXMath.sqrt at bytecode level, which also takes in a float and returns a float.
Original Source code
System.out.println(“Square root Value is “ + getSQRT(x));
Modified Class when decompiled, will have
System.out.println(“Square root Value is “ + nativeImplementation.MMXMath.sqrt(x));
5.2 SIMD Library
The SIMD library in java was built from existing library, written in C and assembly [33]. The SIMD library makes explicit calls to the registers in the Intel processors, using SSE and MMX instruction set. This existing library could be accessed within java via native methods.
Native methods in Java are methods written in some other language usually C or C++. Sun included Java Native Interface since JDK 1.1. The Java Native Interface may be a powerful framework, which could be used to benefit from both worlds Java and C/C++. The JNI renders native application with much of the functionality of Java, allowing the programmers to call Java methods and access Java variables. The Java native interface has several drawbacks, such as runtime, communication overhead and tedious to program.
There are several tools available that promise to automate the native interface wrapper generation, like JNIPP [25], JACE [26], Noodle Glue [27], Start Java [28], JNI Wrapper [34] and JACAW [29]. We used the JACAW package, to generate the wrappers for existing C functions. Although the JACAW generated native wrappers, manual efforts were applied to resolve bugs.
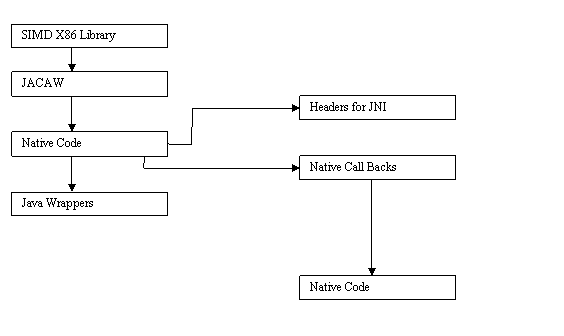

Fig 5.2.1 SIMD Library
5.3 Implementing the SIMD Library in Java
The Java Wrappers for SIMD library were written manually with little help from an existing native method wrapping tool JACAW [29]. Factory design pattern is used as a framework for the Library. While using native methods, the native library must be in the java class path. The native library is a shared object (.so) file in Linux. When a call is made to native method the JVM looks for the library, else throws errors. To ensure proper working of the native methods, these libraries must be included in class path, either manually or dynamically. The framework also ensures that these libraries are in path, before native calls are executed. The framework also detects the existence of MMX support, before attempting to use the native libraries.
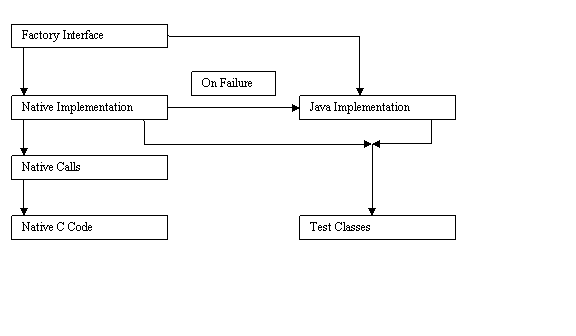
Fig 5.3.1 Factory Interface for SIMD Library
The factory interface is an interface which holds the method definitions for all the methods supported by the Java SIMD Library. The Native implementation and Java Implementation are classes, which implement the Factory Interface. The only difference being the native implementation resolves to native calls, and the Java implementation resolves to pure Java calls, which act as an alternative on failure to load native methods.
Factory
Interface for Math Methods: code extract
public interface MathInterface
{
public double sqrt(double value);
}
Native Implementation
for Math Methods: code extract
public class MMXMathImplementation
implements MathInterface {
public static double sqrt(double
value) {
//Call the Native
Implementation
return
(NativeMath.sqrt(value));
}
}
Java Implementation
for Math Methods: code extract
public class JavaMathImplementation
implements MathInterface {
public static double sqrt(double
value) {
//Call the Native
Implementation
return
(Math.sqrt(value));
}
}
Generic Implementation for Math Methods
public class GenericMath
{
public static double sqrt(double
value){
if(isNativeLibFixed){
return MMXMathImplementation.sqrt(value);
}
else {
return JavaMathImplementation.sqrt(value);
}
}
}
Usage
System.out.println(GenericMath.sqrt(doubleValue));
Please refer Appendix B for a complete
method listing.
5.4 Handling Failures to Load Native Library
To ensure the proper working of the SIMD Library, the shared libraries must be in path, (i.e. .so files for Linux). The JVM attempts to look for the library, when the following lines are encountered.
static {
System.loadLibrary(.SO/.DLL)
}
Failure to the load the library may occur due to (1) Native Library is absent; (2) Native Library is present but is not included in java library path (3) The Native library present is of an older version. The native library errors are fixed, by altering the class path during runtime [35].
Fixing Native Libraries
public class FixNativeLib {
private boolean isNativeLibFixed; public FixNativeLib() { ManageNativeLib manageNativeLib = new ManageNativeLib(); try { //Attempt to load Libraries LoadLibs(manageNativeLib); //Check for MMX if (DetectMMX.detectMMX() == 1){ isNativeLibFixed = true; } else { isNativeLibFixed = false; } } catch (UnsatisfiedLinkError e) { System.out.println("Error, Using pure java methods"); isNativeLibFixed = false; } catch (Exception e) { System.out.println("Error, Using pure java methods"); isNativeLibFixed = false; } }
6. Benchmarks
6.1 SIMD Library
All tests were performed on 2.0 GHz clock speed, Linux PC.
Dhrystone Benchmark analysis, the Dhrystone benchmark was performed for 500000 cycles.
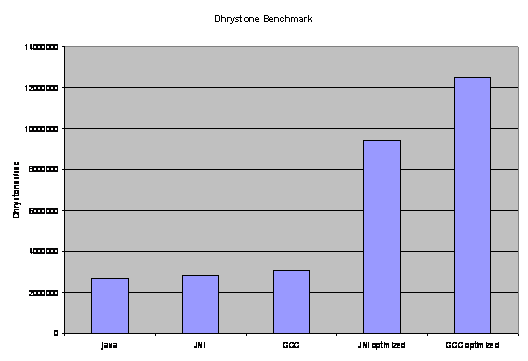
Fig 6.1.1 Dhrystone benchmark analysis
|
Computed using |
Dhrystones |
Time (ms) |
|
JAVA |
2702702 |
185 |
|
JNI |
2841361 |
186 |
|
GCC |
3067936 |
122 |
|
JNI optimized (Vectorized) |
9435564 |
178 |
|
GCC optimized |
12501875 |
98 |
Matrix
multiplication benchmark
Matrix multiplication was performed as a benchmark on M x N matrices. A comparison was made against JAMA (Java Matrix), a library written purely in java and standard JDK. The matrix multiplication was performed for a 100 cycles, in each case.
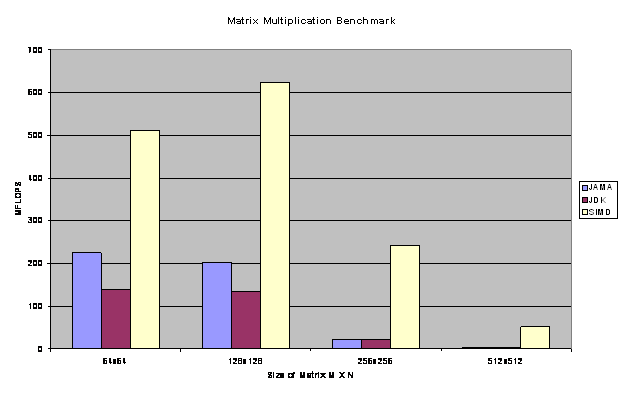
Fig 6.1.2 Analysis of Matrix multiplication
benchmark
|
LIB Used |
Matrix Size M x N |
MFLOPS |
Time in Secs |
|
JAMA |
64X64 |
225.2 |
1.80 |
|
128X128 |
202.428 |
2.072 |
|
|
256X256 |
22.477 |
41.79 |
|
|
512X512 |
3.501 |
306.70 |
|
|
JDK |
64X64 |
139.3 |
2.77 |
|
128X128 |
135.0822 |
3.10 |
|
|
256X256 |
22.155 |
42.405 |
|
|
512X512 |
2.253 |
476.521 |
|
|
SIMD |
64X64 |
511.5 |
0.31 |
|
128X128 |
424.152 |
0.671 |
|
|
256X256 |
242.207 |
3.878 |
|
|
512X512 |
51.067 |
21.026 |
JNI Overhead for SIMD Library
|
Matrix Size |
JNI Overhead
in S |
|
64 X 64 |
0.04 |
|
128 X 128 |
0.09 |
|
256 X 256 |
0.33 |
|
512 X 512 |
1.07 |
6.2 Method Substitution system
Let us consider the program.
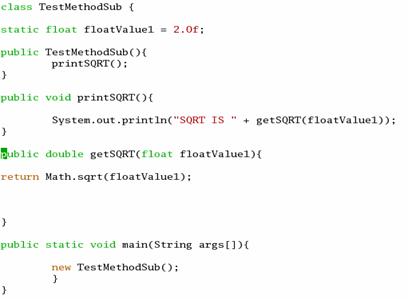
Fig 6.2.1 Sample Java program
We compile the program, and the following output is obtained

Fig 6.2.2 Compile the program
Now we invoke the method substitution system, and choose the .class file generated above.
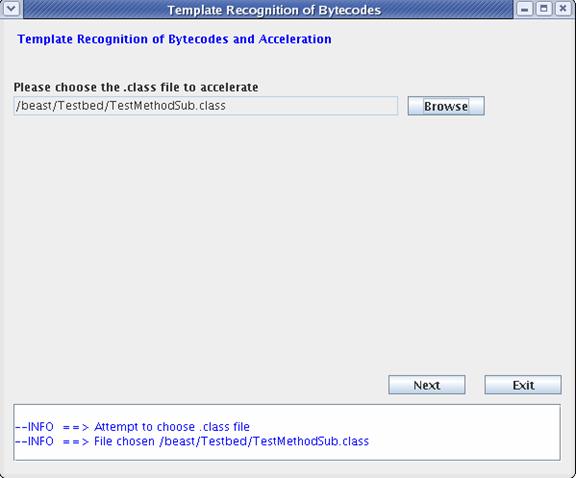
Fig 6.2.3 First screen of the Method
substitution system
Click next, the
method substitution system will span the methodprototype.txt file and list all
the methods which have an entry in the methodprototype.txt and in our test
program. 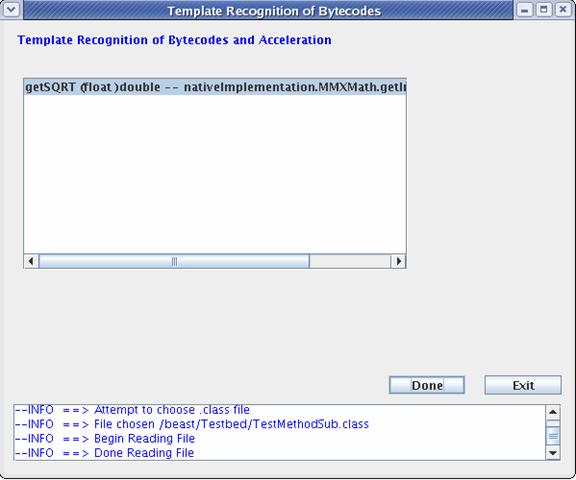
Fig 6.2.4 Second screen, with the methods to be
accelerated are listed
In this case the system detects calls to getSQRT() defined in test program , and allows the user to substitute the calls to this method using SIMD function,
nativeImplementation.MMXMath.getInstance().rsqrt(float)
The method substitution information is obtained from the methodprtotype.txt file.
In this case we use the rsqrt (yields 1/sqrt) from the MMXMath package for test purposes.
Choose the methods to be modified from the list and click done.
Now we attempt to execute the modified class file, without re-compiling.
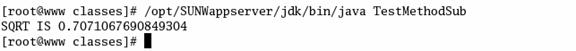
Fig 6.2.5 executing the modified class file,
without re-compiling
The output obtained is different as
nativeImplementation.MMXMath.getInstance().rsqrt(float)
Is called
instead of the actual getSQRT() method.
7. Conclusion
The SIMD package is designed to enhance the performance of some Java programs on CPU architectures with MMX support. The library interfaces with an existing native SIMD x 86 library, to achieve higher performance than pure java. The Library is also coupled with a method substitutions system to fairly automate the process of accelerated method substitution at bytecode level.
8. Future Research
In this thesis we have presented a method to use the underlying CPU architecture to boost performance of Java. The SIMD Library built, supports small set of core functions, which utilize the MMX instruction set. This library can be easily extended to support various other functions in the fields of Numerical computing, Image processing and signal processing. The SIMD Library supports only the Intel processors; this library could be extended to support other processor, like the Motorola G4 processors, with ALTIVEC technology. A new function could be added to the framework to use the Library based on the underlying processor.
The SIMD Library communicates with native code via Java Native Interface. The communication overhead is very high when using JNI, sometimes the communication overhead could kill the performance gains achieved, by native code. Efforts have been made to minimize the communication overhead and optimized usage of code, but errors and inconsistencies may exist. The binary distribution of the SIMD library target the Linux operating systems only, these could be extended to support other operating systems like windows and Mac OS.
The
method substitution system is too strict and solely depends on the text file.
It would be better to devise a method to recognize bottlenecks in code using a
profiler and substitute accelerated library calls.
Appendix A
MMX Instruction Syntax
A typical MMX instruction has this
syntax [8]:
Prefix:
P for Packed
Instruction
operation: for example - ADD, CMP, or XOR
Suffix:
US for Unsigned Saturation, S for Signed saturation.
B,
W, D, Q for the data type: packed
byte, packed word, packed double word, or quad word
As an example, PADDSB is a MMX instruction
(P) that sums (ADD) the 8 bytes (B) of the source and destination operands and
saturates the result (S).
Appendix B
//returns the square root of double
double sqrt(double value)
//returns the square root of float
float sqrtf(float value)
//returns the reciprocal of square root of
double
double rsqrt(double value)
//returns the reciprocal of square root of
float
float rsqrtf(float value)
// returns Difference of 3 x 3 matrix
float[][] mat3Diff(float[][] m1, float[][] m2)
// Multiplication of matrices of size 3 x 3
float[][] mat3Mul(float[][] m1, float[][] m2)
//Scales the matrix of size 3 x 3 using float
float[][] mat3ScaleOf(float[][] arg0, float m)
//Sum of Matrices of size 3 x 3
float[][] mat3Sum(float[][] m1, float[][] m2)
//transpose of matrix of size 3 x 3
float[][] mat3TransposeOf(float[] arg0)
//Difference of Matrices of size 4 x 4
float[][] mat4Diff(float[][] m1, float[][] m2)
//Multiplication of matrices of size 4 x 4
float[][] mat4Mul(float[][] m1, float[][] m2)
//Scale of a matrix of Size 4 x 4
float[][] mat4ScaleOf(float[][] arg0, float m)
//Sum of matrices of size 4 x 4
float[][] mat4Sum(float[][] m1, float[][] m2)
//Transpose of matrix of size 4 x 4
float[][] mat4TransposeOf(float[] arg0)
//Difference of matrix (3 x 3 || 4 x 4) One Dimesional //array
float[] matrixDiff(float[] m1, float[] m2, int
a, int b, int c, boolean t)
//Multiplication of matrix (3 x 3 || 4 x 4)
One Dimesional //array
float[] matrixMul(float[] m1, float[] m2, int
a, int b, int c, boolean t)
//Scale of matrix (3 x 3 || 4 x 4) One Dimesional array
float[] matrixScaleOf(float[] arg0, int retSize, int arg0Size, float m, boolean needCopy)
//Sum of matrix (3 x 3 || 4 x 4) One Dimesional array
float[] matrixSum(float[] m1, float[] m2, int
a, int b, int c, boolean t)
//Transpose of matrix (3 x 3 || 4 x 4) One Dimesional array
float[] matrixTransposeOf(float[] arg0, int
retSize, int arg0Size, boolean needCopy)
//Conjugate of a quaternion
float[] conjugate(float[]
f1)
//Length of quaternion
float length(float[]
f1)
//Length square of quaternion
float lengthSq(float[] f1)
//Multiplication of quaternion
float[] multiply(float[]
f1, float[] f2)
//Normalized quaternion
float[] normalize(float[]
f1)
//Rotation of a quaternion
float[] rotate(float[]
f1, float rads, float x, float y, float z)
//Quaternion to matrix, One Dimensional array
float[] toMatrix(float[] f1)
//Cross of Vectors
float[] vectorCrossOf(float[] f1, float[] f2)
//Difference of vectors
float[] vectorDiff(float[] f1, float[] f2)
//Dot Product of Vectors
float vectorDot(float[] f1, float[] f2)
//Normalize a vector
float[] vectorNormalizeOf(float[] f1)
//Scale a vector
float[] vectorScale(float[] f1, float f2)
//Sum of Vectors
float[] vectorSum(float[] f1, float[] f2)
//Facilitates efficient Addition of huge
block matrices
float[][] BlockAdds(float[][]
f1, float[][] f2)
//Facilitates efficient Subtraction of huge
block matrices
float[][] BlockDiff(float[][]
f1, float[][] f2)
//Facilitates efficient Multiplication of
huge block //matrices
float[][] BlockMul(float[][]
f1, float[][] f2)
//Facilitates efficient scaling on large
block Matrix
float[][] BlockScaleOf(float[][]
f1, float f2)
//Facilitates efficient Transpose of block
matrix
float[][] BlockTarnspose(float[][]
f1)
8. References
[1] Douglas Lyon:
Java Optimization for Super scalar and Vector Architectures
Journal
of Object Technology,
vol. 4, no. 2, 2005, pp. 27-39
[2] Qiaoyin Li:
Java Virtual Machine – Present and near Future
Proceedings of the Technology of
Object-Oriented Languages and Systems, 3-7 Aug 1998
Page: 480
[3] Austin Kim and
Morris Chang:
Java Virtual Machine Performance Analysis with Java Instruction Level
Parallelism and Advanced Folding Scheme.
Performance,
Computing, and Communications Conference,
[4] Kazuaki Ishizaki, Tatushi Inagaki,
Hideaki Komatsu, Toshio Nakatani:
Eliminating Exception Constraints of Java programs for IA-64
Proceedings
of the 2002 International Conference on Parallel Architectures and Compilation
Techniques, page 259
[5] Pascal A. Felber:
Semi-Automatic Parallelization of Java
Applications.
[6] Pedro V. Artigas, Manish Gupta, Samuel P.Midkiff,
Jose E Moreiera:
Automatic
Proceedings
of the 14th international conference on Supercomputing,
[7] Aart J.C. Bik
and Dennis B. Gannon:
JAVAB – A prototype bytecode
Parallelization tool.
Computer Science dept.
[8] MMX
Primer:
http://www.tommesani.com/MMXPrimer.html
[9] Svante Arvedahl:
Java Just In Time Compilation for IA-64 Architecture
[10] Samuel K. Sanseri:
Toward an Optimizing JIT Compiler for IA-64
Master's thesis,
[11] Pedro V. Artigas ,
Manish Gupta , Samuel P. Midkiff , José E. Moreira, High Performance Numerical Computing in Java:
Language and Compiler Issues, Proceedings of the 12th International Workshop on
Languages and Compilers for Parallel Computing p.1-17, August 04-06, 1999
[12] Iffat H. Kazi, Howard. H. Chen, Berdenia Stanely, and David J. Lilja:
Techniques for Obtaining High Performance
in Java Programs. ACM Comput Surv 32(3): pages 213-240, year 2000
[13] Jose
A Standard Java
Array Package for Technical Computing
In Proceedings of the Ninth
[14] Tim Lindholm and Frank Yellin:
Java Virtual Machine
Specification
1999 - Addison-Wesley Longman Publishing Co., Inc.
[15] Ronald. F. Boisvert, Jack. J. Dongarra, Roldan
Pozo, Karin. A. Remington, G.W. Stewart:
Developing Numerical
Libraries in JAVA
ACM Concurrency, Pract. Exp. (
[16] Ian Piumarta and Fabio Riccardi:
Optimizing direct
Threaded code by selective in lining.
INRIA Roquencourt, B.P. 105, 78153
Le
[17] Matthias
Schwab, Joel Schroeder:
Algebraic Java
classes for Numerical Optimizations
Java high performance network computing, 1998 volume 10
Issue 11-13, pages 1155-1164
[18] Jack K. Shirazi:
Java Performance
Tuning
O’Reilly publications, September 2000
[19] Zheng
Weimin, Zheng Fengzhou, Yang Bo, Wang Yanling:
A Java Virtual Machine Design Based on Hybrid Concurrent Compilation Model
Proc conf technology object oriented language system tools, no. tool 36, pp. 18-23. 2000
[20] Vector Signal Image Processing Library:
http://www.vsipl.org
[21] Sun Microsystems:
http://java.sun.com/
[22] JAMA (Java Matrix) high performance
library:
http://math.nist.gov/javanumerics/jama/
[23] Lyon and Rao:
Java Digital Signal Processing
M
& T Books; Book & CD edition (November 30, 1997)
[24] Tory
Alfred, Vijay P Shah, Anthony Skjellum and Nicholas H
Younan:
InAspect:
interfacing Java and VSIPL applications
ACM
Java Grande-ISCOPE Conference Part II, 2002. Volume 17, Issues 7-8, pages
919-940
[25] JNI++:
http://sourceforge.net/projects/jnipp
[26] Jace:
http://sourceforge.net/projects/jace/
[27] Noodle Glue:
www.noodleheaven.net/JavaOSG/javaosg.html
[28] Start Java:
http://sourceforge.net/projects/startj
ava
[29] Jacaw:
http://users.cs.cf.ac.uk/Yan.Huang/research/JACAW/JACAW.htm
[30] ASM:
[31] BCEL:
[32] Javassist:
http://www.csg.is.titech.ac.jp/~chiba/javassist/
[33] SIMD Library:
http://sourceforge.nete/projects/simdx86
[34] JNI Wrapper:
[35] Dr. Douglas Lyon:
[36] MMX Article:
http://www.netpanel.com/articles/computer/mmx.htm